TAO表示train、adapt、optimize,TAO Toolkit是nvidia TAO框架的低代码版本,使用者无需专业的AI知识即可轻松构建高准确度的AI模型,在英伟达设备上做到训练部署一条龙。
流程参考快速上手tao toolkit
1、注册英伟达开发者账号,略。
2、去ngc官网ngc官网目录 右上角登陆,选用英伟达账号登陆。
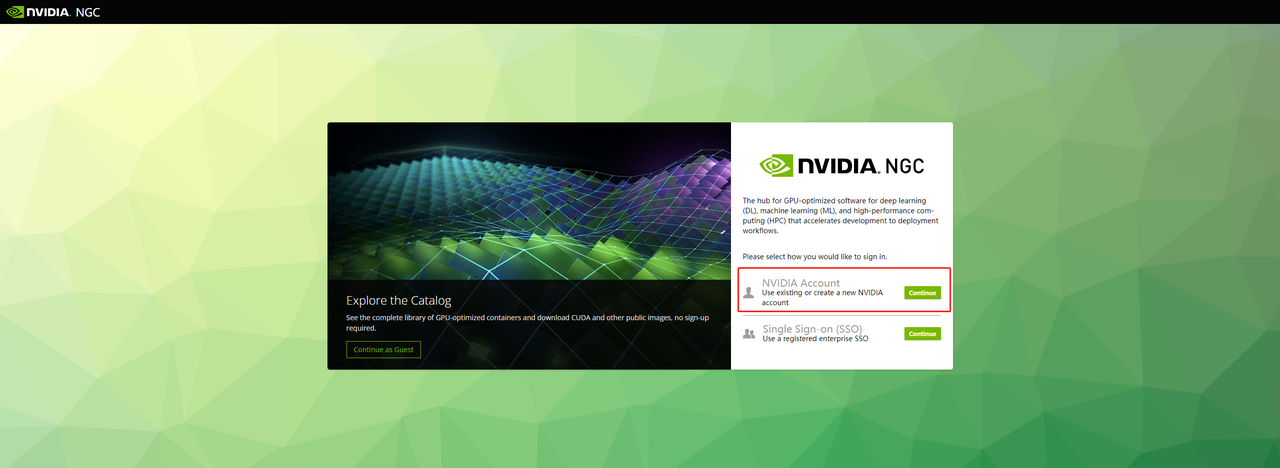 3、回到ngc首页,右上角点卡自己的账号,点Setup,此时里面会出现Generate API Key选项卡,点击Get API Key进入。
3、回到ngc首页,右上角点卡自己的账号,点Setup,此时里面会出现Generate API Key选项卡,点击Get API Key进入。
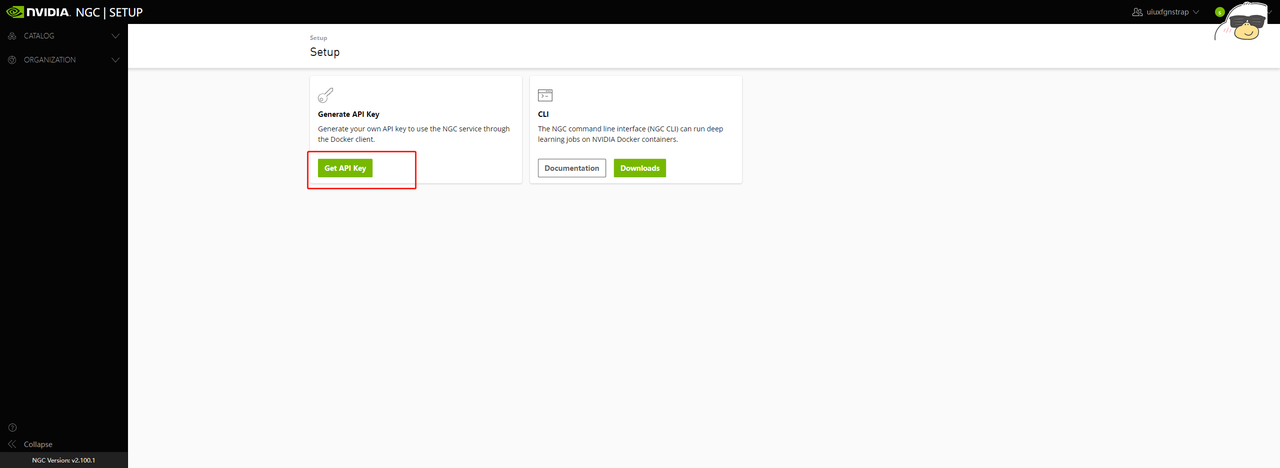 4、点击Generate API Key,下方会生成专属Key值,这个Key需要记下来,以后都用这个Key登录,如果忘记需要到这里重新生成。生成新的Key后,之前的Key自动作废。下图中没点,仅作示例。
4、点击Generate API Key,下方会生成专属Key值,这个Key需要记下来,以后都用这个Key登录,如果忘记需要到这里重新生成。生成新的Key后,之前的Key自动作废。下图中没点,仅作示例。
 5、回到要部署TAO的机器上,这里需要支持gpu的docker和一定版本的显卡驱动(太旧的不行),具体版本可以参考安装需要的软件版本 ,新版docker已经可以支持gpu,因此不用特意安装nvidia docker,docker有问题更新docker,显卡驱动更新略。输入命令登录docker:
5、回到要部署TAO的机器上,这里需要支持gpu的docker和一定版本的显卡驱动(太旧的不行),具体版本可以参考安装需要的软件版本 ,新版docker已经可以支持gpu,因此不用特意安装nvidia docker,docker有问题更新docker,显卡驱动更新略。输入命令登录docker:
docker login nvcr.io
用户名是$oauthtoken,密码是上一步生成的Key。登录成功会显示"Login Succeeded"。
6、回到ngc官网账号的Setup界面,安装ngc cli工具,这个工具不单独安装也可以,下面TAO的示例工程中会带安装步骤,但是可能会带来额外的问题,因此这里我们选择手动安装:
ngc-cli工具介绍
Introduction to NGC CLIsIntroduction to NGC CLIs The NGC CLIs are command-line interfaces for managing content within the NGC Registry. The CLI operates within a shell and lets you use scripts to automate commands. - View a list of GPU-accelerated Docker container images, pre-trained deep-learning models, and scripts for creating deep-learning models. - Download container images, models, and resources. NGC Registry CLI The NGC Registry CLI is available to you if you are logged in with your own NGC account or with an NGC Private Registry account, and with it you can - View a list of GPU-accelerated Docker containers available to you as well as detailed information about each container image. - See a list of deep-learning models and resources as well as detailed information about them. - Download container images, models, and resources. - Upload container images, models, and resources. - Create and manage users and teams (available to NGC Private Registry administrators).
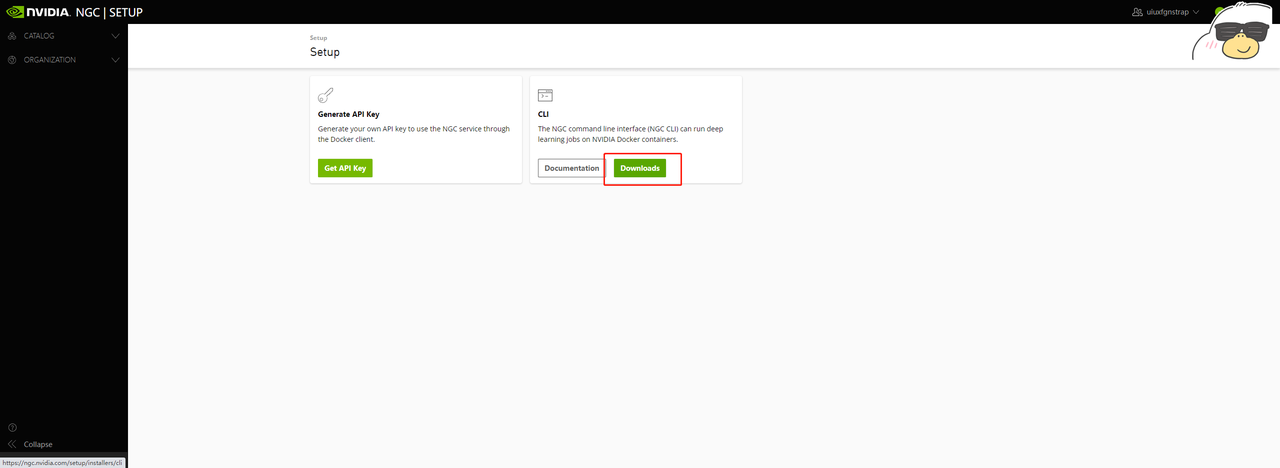
 可以看到提供不同版本的下载,linux直接用命令行安装即可:
可以看到提供不同版本的下载,linux直接用命令行安装即可:
# 下载
wget --content-disposition https://ngc.nvidia.com/downloads/ngccli_linux.zip && unzip ngccli_linux.zip && chmod u+x ngc-cli/ngc
# 验证下载文件完整性
find ngc-cli/ -type f -exec md5sum {} + | LC_ALL=C sort | md5sum -c ngc-cli.md5
# 配置到环境变量 .bashrc
export PATH=$PATH:到ngccli的路径/ngc-cli
# 设置ngc配置文件
ngc config set
配置文件需要填上面生成的API Key,其他默认即可,有其他需要可以去/home/user/.ngc/config随时改,user替换成当前用户。
7、本地创建TAO运行的虚拟环境,此处用conda创建:
conda create -n launcher python=3.6
conda activate launcher
8、安装Jupyter Lab和Tensorboard
pip install jupyter
pip install tensorboard
9、下载示例工程:
wget --content-disposition https://api.ngc.nvidia.com/v2/resources/nvidia/tao/cv_samples/versions/v1.4.0/zip -O cv_samples_v1.4.0.zip
unzip -u cv_samples_v1.4.0.zip -d ./cv_samples_v1.4.0 && rm -rf cv_samples_v1.4.0.zip && cd ./cv_samples_v1.4.0
例子下载的版本是v1.4.0,这个英伟达会一直更新,如有需要下载其他版本,可以去tao toolkit cv samples版本信息 查看或者去ngc首页左侧目录选Resources->搜索框搜cv->找到TAO Toolkit Computer Vision Sample Workflows:
 10、进入示例工程目录下并激活虚拟环境,运行jupyter notebook,可选择后台运行防止远程掉线或误操作关闭带来问题:
10、进入示例工程目录下并激活虚拟环境,运行jupyter notebook,可选择后台运行防止远程掉线或误操作关闭带来问题:
nohup jupyter notebook --ip 0.0.0.0 --port 8888 --allow-root >/dev/null 2>&1 &
至此已经可以通过网页打开jupyter notebook远程操作训练服务器。
11、使用TAO训练需要的配置
TAO实际的训练过程并不在训练机器的本地而是运行在docker容器中,我们不需要关注训练的细节问题,不过训练数据和配置文件都是在本地的,因此需要配置本地路径到docker容器内路径的映射关系。这部分映射关系在示例工程中已经为我们配置好了,只要在示例工程开头部分找到需要配置路径的位置修改成自己的路径即可。以bpnet为例:
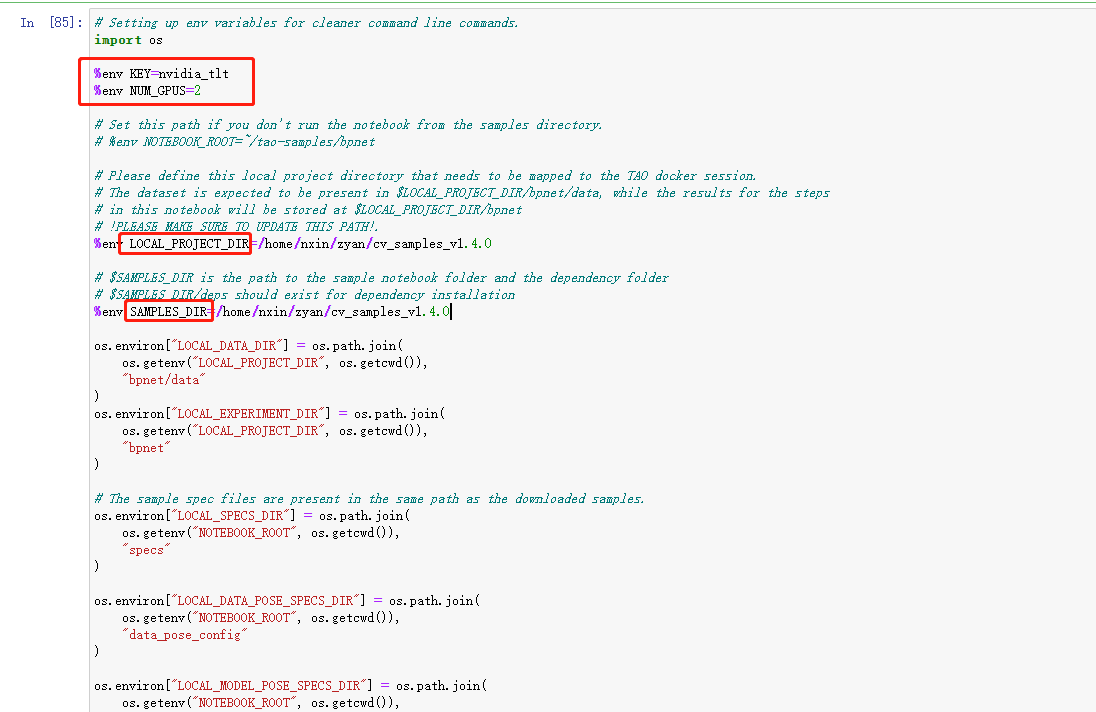 模型的KEY已经填好,建议修改成自己的密码对模型加密,并且要记住这个key,后续所有对模型的操作(包括部署)都需要这个key,没有key是无法对tao toolkit的模型做任何操作的,如果部署后转换成TensorRT形式的模型则不受key限制。
模型的KEY已经填好,建议修改成自己的密码对模型加密,并且要记住这个key,后续所有对模型的操作(包括部署)都需要这个key,没有key是无法对tao toolkit的模型做任何操作的,如果部署后转换成TensorRT形式的模型则不受key限制。
还要修改工程用到的gpu数量、本地bpnet工程路径、本地示例工程路径这三个。其他所有路径关系都已经配置好,包括docker容器的映射路径等,顺着往下点即可,后面会出现两种路径,本地路径和容器路径,需要区分开,我们只需要操作本地路径,容器路径用默认值即可,不需要做改动(分不出来也没事都配置好的,不过数据下载会出现网络问题,如果自己下载放过去需要注意路径问题。模型导出同样有路径问题)。
12、示例工程中有一步安装TAO:
!pip3 install nvidia-tao
默认安装最新版,但是不同版本使用的tensorrt版本不同,版本对应关系可以去tao toolkit版本信息 查看。TAO的版本与triton镜像的版本对应,例如3.0-22.05版本的TAO Toolkit,对应的triton镜像是nvcr.io/nvidia/tritonserver:22.05-py3 ,22.05对22.05,22.02对22.02,如果想让TAO转出来的tensorrt模型能在tritonserver:22.02镜像中运行,安装时需要指定版本号3.0-22.02(依然可能因为不同系列显卡算力不同而无法运行,因此版本选取不是必须的,14会介绍其他方法)。
13、TAO的训练流程如下:
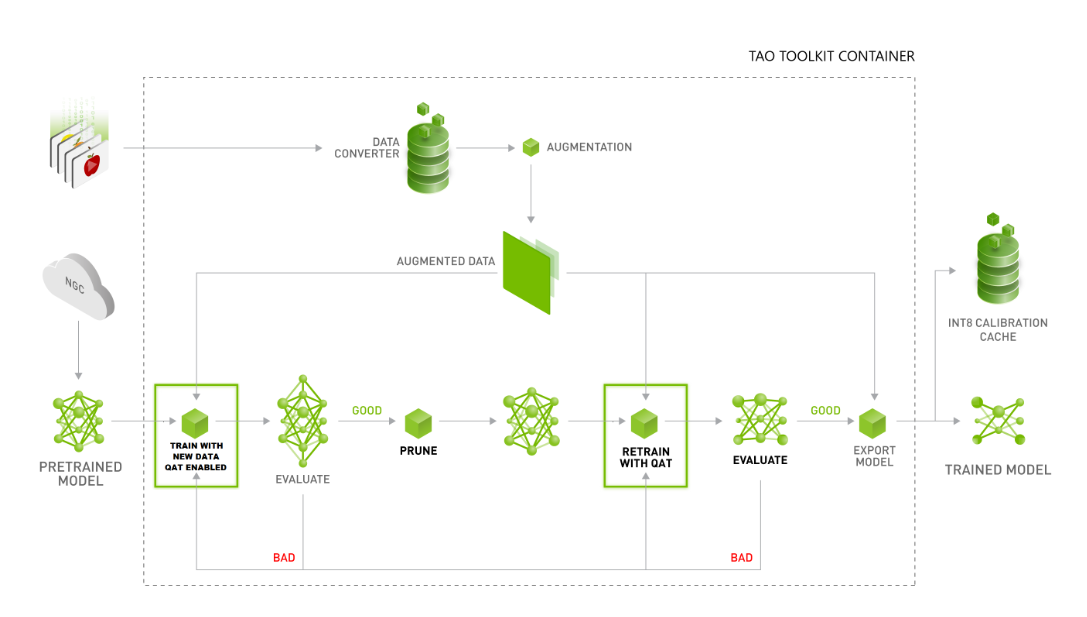 把数据和预训练模型传进容器train,train结束进行评估,如果评估结果不好,应该加新数据再train,如果评估结果达到要求,进行剪枝,得到剪枝过的模型retrain,retrain的结果好可以直接走部署流程,结果不好重新retrain。
把数据和预训练模型传进容器train,train结束进行评估,如果评估结果不好,应该加新数据再train,如果评估结果达到要求,进行剪枝,得到剪枝过的模型retrain,retrain的结果好可以直接走部署流程,结果不好重新retrain。
需要注意retrain出来的模型不能再剪枝,只有train出来的模型才能剪枝。train和retrain表示模型的不同阶段,train的参数、剪枝的参数、retrain的参数都可以调整,但是需要使他们工作在各自的环节,不能简单理解为训练和再训练容易产生混淆(只要没剪枝,train多少次都在train阶段,但是可能已经再训练多次)。
14、关于模型部署
如果直接在示例工程中导出tensorrt模型,tensorrt的版本取决于示例工程python环境安装的nvidia-tao版本,显卡算力取决于训练服务器的显卡算力,这样部署在其他机器或者容器中时,显然会出现版本、算力不匹配的问题,官方查询算力链接:英伟达产品算力查询。
我们需要示例工程中导出的.etlt模型用于部署。在部署服务器,我们当然可以再像前面那样部署TAO,在配置好对应模型的路径映射后,找到下面的tao converter语句把里面的模型换成要部署的模型进行转换,这样的好处是转换出的tensorrt版本和训练环境的tensorrt版本一致,同样问题是比较麻烦。
另一种方法是用ngc cli工具下载tao-converter,直接用这个转换工具转:
# <latest_version> 换成要下载的版本号,/path/to/download/directory 指定下载地址
ngc registry resource download-version nvidia/tao/tao-converter:<latest_version> --dest /path/to/download/directory
sudo apt-get install libssl-dev
export TRT_LIB_PATH=”/usr/lib/x86_64-linux-gnu”
export TRT_INC_PATH=”/usr/include/x86_64-linux-gnu”
# 进入上面下载的tao-converter工具目录
# 加执行权限
chmod +x tao-converter
# 运行转换命令,同TAO中的命令
./tao-converter /home/nxin/zyan/peoplenet_model/resnet34_peoplenet_int8.etlt -k tlt_encode -t fp16 -e /home/nxin/zyan/peoplenet_model/resnet34_peoplenet_fp16.engine -p images,1x3x544x960,8x3x544x960,64x3x544x960 -d 3,544,960
tao-converter的版本信息同样去ngc查看tao converter版本信息 ,Overview中有tao-converter的参数说明。这样转会带来的问题是ngc官网只提供了有限版本的tao-converter,它们对应的TensorRT版本也就那几个,可能和训练服务器的TensorRT、我们使用的triton镜像版本都不一致,triiton镜像对应的TensorRT版本去这里查看triton版本信息。
15、in8模型
TAO提供模型的量化,这个过程是在TensorRT内部完成,不要我们参与。我们需要做的是选择10%-20%训练数据生成量化模型的标定文件,示例工程运行中会生成如calibration.320.448.deploy.bin或在ngc官网下载的可部署模型中带的txt文件,这些都是int8模型的标定文件,如果需要部署int8的tensorrt模型,一定需要标定文件。标定文件格式大致如下:
 会显示网络每层标定的参数,要注意开头,会给出标定文件的TensorRT版本。由于量化是TensorRT完成,在实验中发现TensorRT版本会影响标定文件。
会显示网络每层标定的参数,要注意开头,会给出标定文件的TensorRT版本。由于量化是TensorRT完成,在实验中发现TensorRT版本会影响标定文件。
举个例子:我们去官网下载一个老版本的可部署模型,int8部署,给的标定文件是老版本的Tensorrt,但是部署模型要转成新版本TensorRT模型,此时用这个老版本标定文件,模型的输出数据会异常,需要标定文件TensorRT版本和部署模型的TensorRT版本一致才行。
目前尝试出两种方法解决:
(1)fp16部署,这样就绕开标定文件了;
(2)用TAO选取对应网络生成对应TensorRT版本的标定文件,此时要注意示例工程的nvidia-tao版本(TensorRT)和标定数据的选取。
16、可部署模型和可训练模型
TAO提供两种模型,一种是可训练模型,可以正常训练部署;一种是可部署模型,会在模型中加入一些不可训练的后处理层,只用作部署不可训练。
在export步骤中加--sdk_compatible_model参数,导出可部署模型。
这里有个问题,官网这里只是说加了一些不可训练的后处理层,但是这些后处理具体处理了哪些并没有说,而且TAO本身尽管提供了推理功能,但是在部署层面没有提供模型的预处理后处理文件。因此这里做的时候必须对模型输入输出的内容了解才行,ngc官网model下也会提到这些model用到哪些论文,看不懂模型的输出内容需要学这些论文。
英伟达github的仓库下提供了一个triton部署的仓库,包括分类、检测、分割等网络预处理和后处理,docker部署,地址tao toolkit triton部署官方仓库 ,不过这里面也没有包括所有网络,比如2D人体姿态(输出同openpose)就没有,需要自己写。
去官方模型提供地址 搜对应的网络,两种模型官方均会提供。
17、可视化训练过程
pip安装tensorboard,--logdir指定到训练的文件夹或者下面的event文件夹,网页查看。
nohup tensorboard --logdir=/home/nxin/zyan/cv_samples_v1.4.0/bpnet/models/exp_m1_retrain/ --host 0.0.0.0 --port 6006 >/dev/null 2>&1 &
未完待续,持续更新...