python环境:anaconda base环境,python版本3.9.7
CMake版本:3.24.1 cmake下载
opencv版本:4.6.0
vs版本:2019社区版
cuda Toolkit版本:11.3.1 cuda-toolkit下载,nvcc -V显示版本
cuDNN版本:8.2.1 cuDNN下载
英伟达cuda相关下载需要注册英伟达账号,vs2019和anaconda安装省略。
cuda toolkit和cuDNN版本需要对应,cuda11的试了几个应该都没问题,再老的不清楚能不能用。vs版本老一些没关系。
从仓库下载指定版本opencv,需要安装git(git下载)。
git clone -b 4.6.0 https://github.com/opencv/opencv.git # 从仓库下载4.6.0 opencv
从仓库下载指定版本opencv-contrib,需要和opencv版本保持一致。
git clone -b 4.6.0 https://github.com/opencv/opencv_contrib.git # 从仓库下载4.6.0 opencv-contrib
下面使用cmake-gui操作。
1、打开cmake-gui,指定opencv工程路径后点Configure

2、选安装的vs版本,使用本机默认编译器。第二行空着的是生成选项,新版cmake默认是x64,64位机器就不用填,老版本cmake默认可能是32位的。需要手动填x64

3、第一次Configure结束,出来一堆编译的选项,中间遇到什么错误警告都不用管,反正后面还要再点

4、搜JAVA,BUILD_JAVA取消勾选

5、搜TESTS,BUILD_TESTS取消勾选

6、搜VTK,WITH_VTK取消勾选

7、搜NONFREE,勾选OPENCV_ENABLE_NONFREE

8、搜PYTHON3,能勾选的全勾选,环境地址会默认给到anaconda的base环境,不用改到时候用base环境即可

9、搜CUDA,全部勾选

10、点击Add Entry,增加WITH_CUDNN配置

11、搜MODULES,OPENCV_EXTRA_MODULES_PATH设置为opencv_contrib的modules文件夹路径

12、再次点击Configure,警告不用管,一般会遇到很多下载失败,都是网络的问题,我这边科学上网换几个节点接着点Configure就好了,没有科学上网的可以查下怎么单独下这些失败的文件,有点啰嗦这里就不写了
 13、没有错误和失败,警告无所谓,点击Generate
13、没有错误和失败,警告无所谓,点击Generate

14、生成结束用vs打开项目
15、上方选到Release x64,右键ALL_BUILD,点击生成

16、安装成功
 17、编译安装的opencv无法直接用pip或conda查看,打开base环境命令行,输入
17、编译安装的opencv无法直接用pip或conda查看,打开base环境命令行,输入python -c "import cv2; print(f'OpenCV: {cv2.__version__}')"看到弹出opencv版本4.6.0说明成功安装
 18、查看本机是否有可用的cuda设备,大于等于1说明gpu可用,python调用gpu版本的opencv需要用cv2.cuda中的方法,这部分是没有对应python代码的,因此pycharm无法跳转到方法的定义和代码处,用法需要查看对应版本的opencv文档(opencv4.6.0 cv2.cuda包含的方法)
18、查看本机是否有可用的cuda设备,大于等于1说明gpu可用,python调用gpu版本的opencv需要用cv2.cuda中的方法,这部分是没有对应python代码的,因此pycharm无法跳转到方法的定义和代码处,用法需要查看对应版本的opencv文档(opencv4.6.0 cv2.cuda包含的方法)
import cv2
print(cv2.cuda.getCudaEnabledDeviceCount())
简单使用
以我最近在做的一个任务里的透视变换代码为例子,cpu版本的:
result = cv2.warpPerspective(imageA, H, (imageA.shape[1] + imageB.shape[1], imageA.shape[0]))
result[0:imageB.shape[0], 0:imageB.shape[1]] = imageB
GPU版本的:
cuMatA = cv2.cuda_GpuMat()
cuMatA.upload(imageA)
result = np.zeros((imageA.shape[0], imageA.shape[1] + imageB.shape[1], 3), dtype=np.uint8)
cuMatr = cv2.cuda_GpuMat()
cuMatr.upload(result)
stream = cv2.cuda_Stream()
cv2.cuda.warpPerspective(src=cuMatA, dst=cuMatr, M=H, dsize=(imageA.shape[1] + imageB.shape[1], imageA.shape[0]), stream=stream)
result = cuMatr.download()
result[0:imageB.shape[0], 0:imageB.shape[1]] = imageB
可以看到opencv gpu版的使用相比cpu只是多了三步:
1、声明gpu使用的矩阵cv2.cuda_GpuMat()
2、把cpu上ndarray形式的矩阵转换成gpu形式的并上传到gpu,cuMatA.upload(imageA)
3、gpu形式的矩阵无法直接使用,需要把数据从gpu下载回cpu使用,cuMatr.download()
stream我理解的是数据在cuda层面的异步,上面代码数据上传、计算、下载是线性的,通过stream设置可以让他们异步进行,用于海量数据处理。stream暂时没仔细研究,不过找了篇讲这个的文章先mark下。opencv的cuda stream在python中的应用
测试下项目中使用gpu透视变换和cpu透视变换的速度:
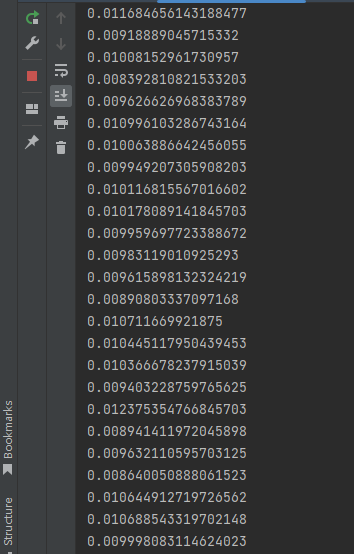
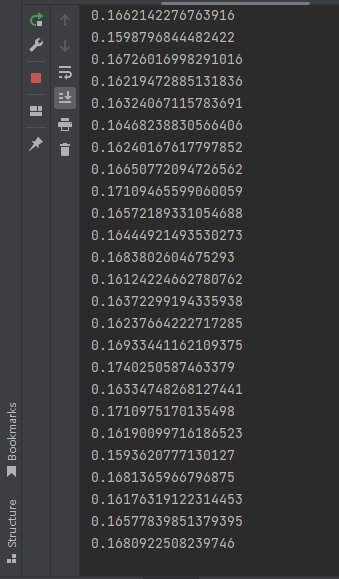
cpu一帧耗时:
gpu一帧耗时:
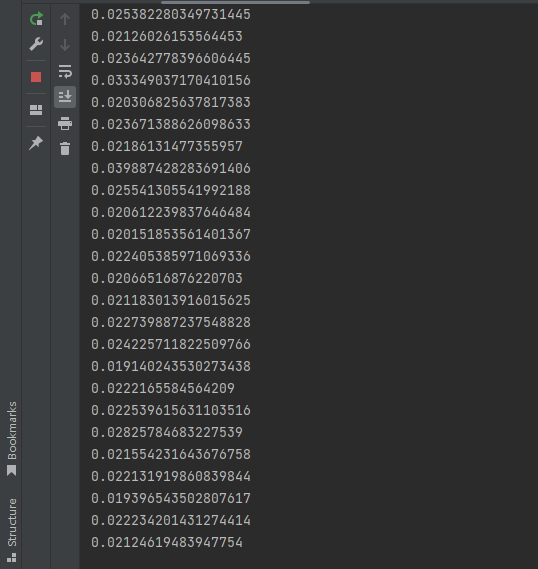
可以看到结果cpu速度差不多比gpu快一倍,可见数据的上传下载还是非常耗时的,不是用gpu做矩阵运算一定比cpu快,所以项目暂时选择cpu版的。
项目还用了鱼眼矫正,可以查到4.6.0版本cv2.cuda下没有fisheye模块,难道gpu版本opencv白折腾了,测一下和之前的速度对比,代码一行没改。
cpu版本:
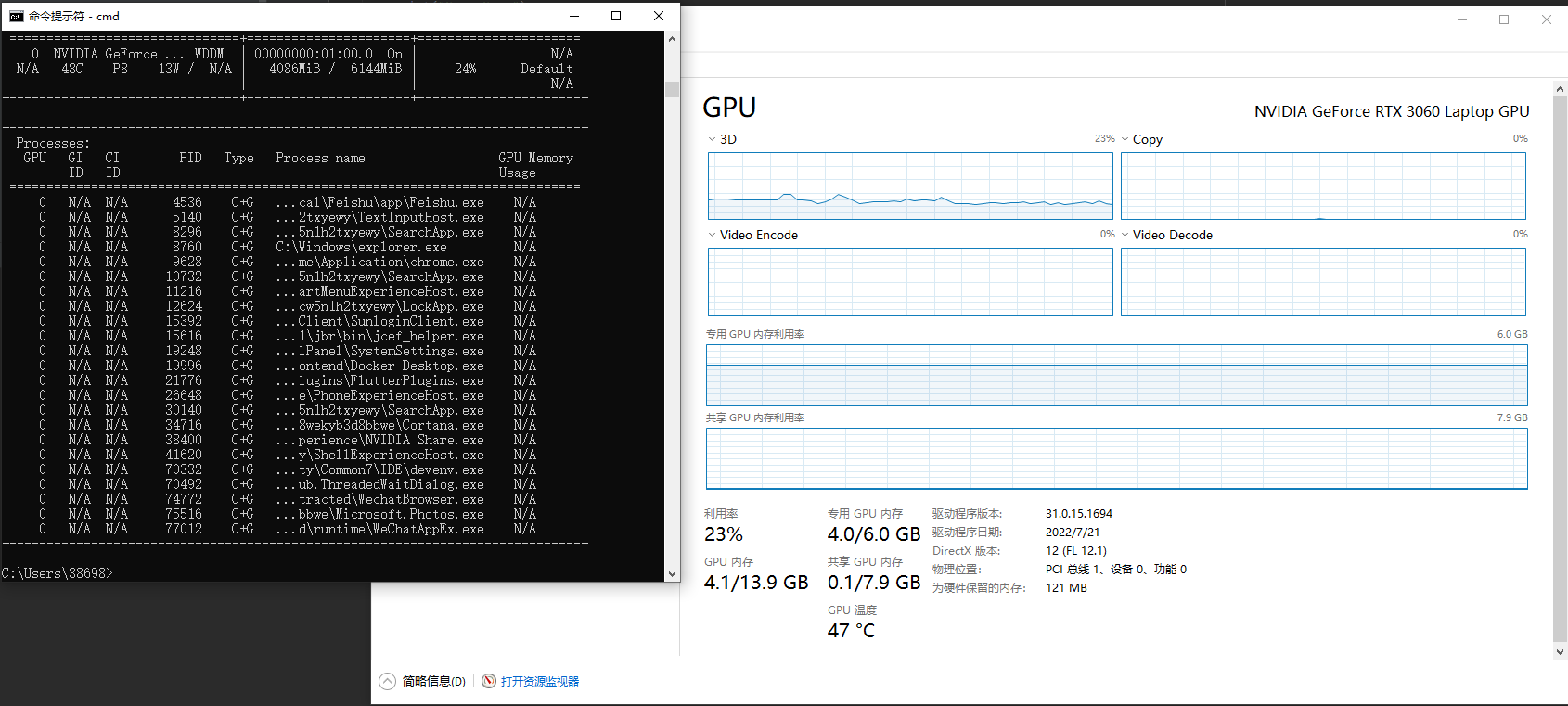
gpu占用:
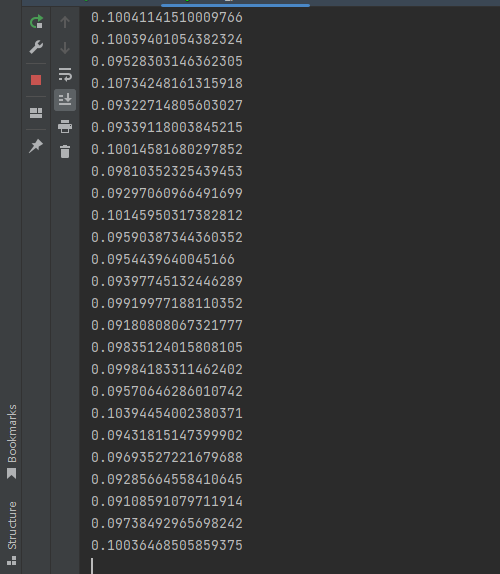
gpu版本:
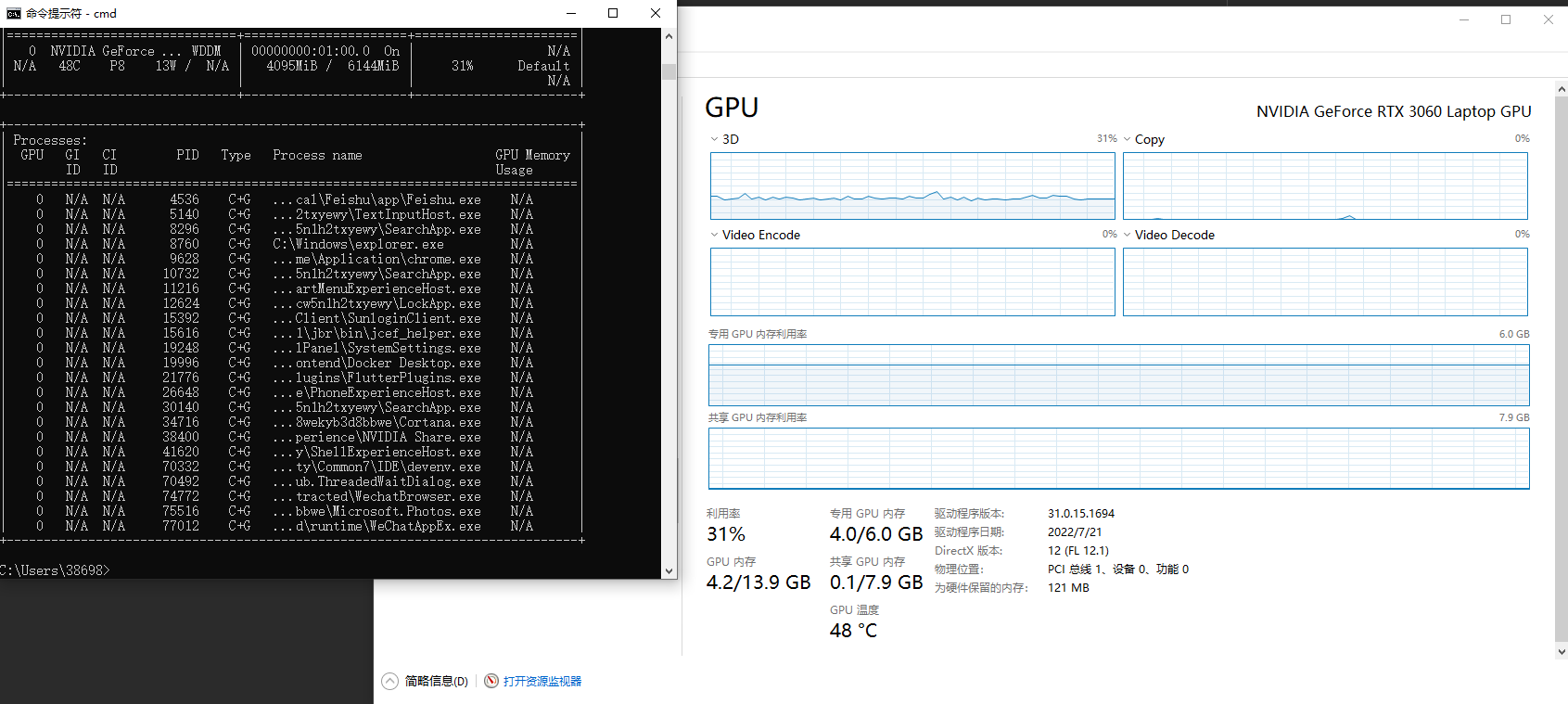
gpu占用:
gpu版本opencv的用时比cpu版本一帧节约大概1/3的时间,还是有用的。
nvidia-smi查看gpu使用情况都没有找到对应的python进程。不过用任务管理器看,运行gpu版本opencv的时候gpu利用率高一些,可能gpu版本opencv以一种我暂时无法理解的方式work了?不清楚原因,此处存疑。