预计阅读时间:39 分钟
openmmlab介绍
openmmlab系列框架在2023年全面进入2.0时代,官方把自监督mmselfsup和分类mmclassification两个项目合并成mmpretrain。
openmmlab 2.0系列底层是有一些变化的,最大变化是从mmcv中抽离出功能更强大的mmengine。新的项目我还没仔细看过,目前简单理解就是轮子更多、用的更爽。
从mmpretrain这种更上层的应用项目看,基本没什么变化。底层封装的完善,上层应用调包,皆大欢喜。
如果熟悉openmmlab系列构建方式,diy上层应用是比较简单的。当然必须会用pytorch,mm是对pytorch的包装和扩展,对pytorch是完全兼容的。
前置知识需要了解一下python中抽象基类的概念,类似c++中的虚函数。mm系列使用python中注册器的思想完成对抽象基类的继承,这部分对刚接触mm系列的新手来说会比较绕,熟悉mm的老手也容易晕,因为各种基类加继承加配置实在是太多。
个人使用的感受是这样的:尽管框架从项目结构上已经尽可能分得清晰,但人能处理的问题复杂度是有限的。哪怕是一个很简单的东西,当它堆叠很多层,人总会在一个阈值之后出现遗忘或混淆等问题,很难像计算机一样保持记忆和逻辑。再清晰的框架如果分了太多层和类,使用时难免会觉得繁琐。
还好我们大部分要做的事情只是搭积木:这时基本只需要关注配置。或是对某一层积木稍加改造:这时需要关注某一个模块的代码。这些操作的复杂度都不高,和使用pytorch模板是类似的。
想要具体学习可以通过项目代码、文档、知乎上OpenMMLab官方号学习,尤其是知乎官方号从注册器到钩子都有从零实现和原理讲解。熟悉底层实现后项目+文档可以快速上手具体项目,整个学习路径可以说做的非常好。
版本说明
mmpretrain官方仓库
文章中修改组件时拉取的是最新tag v1.0.0rc7,修改方法对于后续更新应该是兼容的(当然可能这个项目又又又升级合并到一个新仓库就不得而知)。
同时我不认为官方会在后续项目更新中加入对回归任务的支持,因为加入这个功能并不复杂,现在还没有只能说明官方认为没有必要(或者说会破坏项目的美感、设计一类的因素)。
默认大家分类任务都是能跑起来的。
思路
回归任务选取的backbone是swin transformer v2,直接从仓库看这个文件的配置,当然目前这些配置都是针对分类任务的:
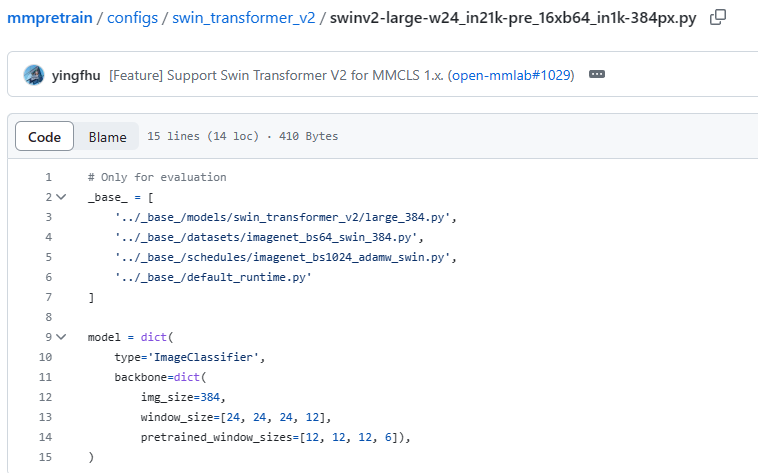
看不出什么,封装了一大堆文件,只能一个一个去看,先看_base_下第一个文件,路径在models下,那这应该是一个模型文件,看一看具体内容:
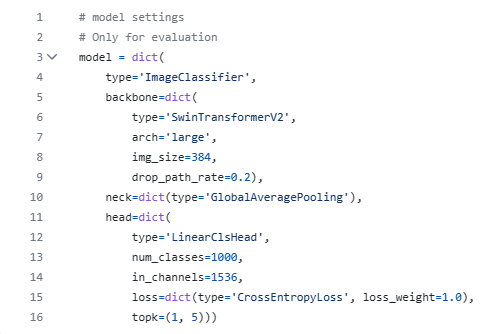
看到只有一个model,里面写了一堆模型的配置,看看哪些和回归任务相关:
1、type:默认给了个ImageClassifier,回归任务和分类任务的类型应该不能复用吧?这里先插个眼,以我们的认知大概率后面需要重写的
2、backbone:提取特征,应该没变化
3、neck:分类用的全局平均汇聚,这个neck回归也能用,这部分不用改
4、head:接个线性分类头。这里有一点不对劲,参数里有个num_classes,说明这个头是针对分类任务的,估计要自己改个回归头出来。loss用的交叉熵,分类用这个,但是对于回归任务loss一般用mae或mse,损失函数可能也需要自己实现
第二个文件在datasets下,可见是有关数据集的配置:

分析:
1、dataset_type:默认给的ImageNet,这个配置文件本来是给人复现实验用的,我们读取肯定需要自定义数据集。按照认知自定义数据集官方肯定有实现,不过需要确定一下支不支持回归,可能可以拿来直接用
2、data_preprocessor:数据预处理流程,这部分是单独实现的,看到里面有参数num_classes可以预见这个方法大概率要重写
3、train_pipeline:应该不用改,回归也是读图片,分类能用的数据增强在回归也都能用
4、train_dataloader:这个应该和回归有关系,回归的gt应该通过标注文件给,ann_file到时候应该指定自己的标注文件,其他采样的方法没影响
5、val_evaluator:评价器必须重写,回归任务没有准确率,需要重写一个回归的评价指标
第三个文件在schedules下,调度器负责模型的训练,任务变了按理说训练方式肯定也会有所改变,但沿用之前的未尝不可(又不是不能跑):

第四个文件是一个默认的运行时配置,可以看到都是些功能性配置,和任务类型关系不大:

有了上面的分析,我们对于修改哪些模块大概是成竹在胸,mm系列对代码修改的位置是固定,在项目名的文件夹下有具体实现:
需要注意的是,在哪一级目录新增类或方法(用装饰器修饰),千万不要忘记在同级目录的__init__.py下添加实现的类或方法名称,只要添加了对应名称,则在mm对应模块中完成注册,可以通过mm正常流程调用。实现的原理可以在文章开头给的建议中找到了解和学习的方法。
这样一看,使用mm系列框架和pytorch模板似乎没什么不同,只不过多了注册的步骤,还是非常简单的。
上面的分析先从模型开始的,不过正常逻辑应该先关注数据集,接下来我们先从上面分析的数据集改起。
增加回归任务相关类和方法
数据集
1、dataset_type
从mmpretrain/datasets中找到自定义数据集custom.py,里面CustomDataset类的注释已经把用法写的很清楚,这些内容官方文档上也是有的,不过考虑到mm系列文档的地址似乎经常404,文章中就不给具体地址请大家去搜官方文档找自定义数据集用法即可。
稍微看下非常符合我们的需求:
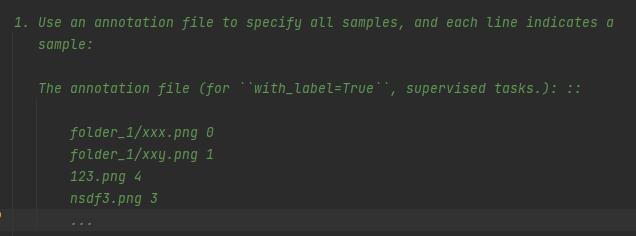
我们的修改思路应该是把分类的label改成回归的target,这样做可以兼容分类可用的数据增强方法,包括mixup这种需要混合标签的增强方式。需要注意的是,分类的label都是整数,如果当成回归的target需要支持float。
在mmpretrain/datasets下新建regression.py:
# Copyright (c) OpenMMLab. All rights reserved.
from mmengine.fileio import (get_file_backend, list_from_file)
from mmpretrain.registry import DATASETS
from .custom import CustomDataset
@DATASETS.register_module()
class RegressionDataset(CustomDataset):
"""A dataset for regression tasks.
This dataset extends the `CustomDataset` and modifies the `load_data_list`
method to allow for float labels instead of integer labels.
"""
def load_data_list(self):
"""Load image paths and gt_labels."""
if not self.ann_file:
samples = self._find_samples()
elif self.with_label:
lines = list_from_file(self.ann_file)
samples = [x.strip().rsplit(' ', 1) for x in lines]
else:
samples = list_from_file(self.ann_file)
# Pre-build file backend to prevent verbose file backend inference.
backend = get_file_backend(self.img_prefix, enable_singleton=True)
data_list = []
for sample in samples:
if self.with_label:
filename, gt_label = sample
img_path = backend.join_path(self.img_prefix, filename)
info = {'img_path': img_path, 'gt_label': float(gt_label)}
else:
img_path = backend.join_path(self.img_prefix, sample)
info = {'img_path': img_path}
data_list.append(info)
return data_list
新建RegressionDataset类,继承CustomDataset。重写load_data_list方法,和相比父类只需要把标签真值gt_label用float类型读入。
下面给一个生成标签的函数:
def generate_annotation_file(image_dir: str, annotation_file: str):
"""
遍历指定的图片文件夹,获取图片的路径和标签,并将这些信息保存到一个文件中。
Args:
image_dir (str): 图片所在的文件夹路径。
annotation_file (str): 用于保存标注信息的文件路径。
Returns:
None
"""
annotations = []
for root, _, files in os.walk(image_dir):
for file in files:
if file.endswith(('.jpg', '.jpeg', '.png', '.bmp', '.JPG', '.JPEG', '.PNG', '.BMP')):
full_path = os.path.join(root, file)
rel_path = os.path.relpath(full_path, image_dir)
label = get_label(file)
annotations.append(f"{rel_path} {label}")
with open(annotation_file, "w") as f:
for annotation in annotations:
f.write(f"{annotation}\n")
print(f"Annotation file has been saved to {annotation_file}")
get_label(file)默认用户应该实现一个名为get_label的函数从图片名获取回归真值,用户可以用自己的方法获取真值。
最后在mmpretrain/datasets/__init__.py中增加RegressionDataset完成注册即可,后面的修改都是这个套路,关于添加注册不再赘述。
关于注册有一个很简单的鉴别方法,就是如果实现一个功能后,在调用的时候报错说没找到这个类或方法,多半是忘记注册导致。
2、data_preprocessor
这部分实现mmpretrain/models/utils/data_preprocessor.py,照着分类的改一改,新增回归的预处理方法:
@MODELS.register_module()
class RegDataPreprocessor(BaseDataPreprocessor):
"""Image pre-processor for regression tasks.
Args:
mean (Sequence[Number], optional): The pixel mean of R, G, B channels.
Defaults to None.
std (Sequence[Number], optional): The pixel standard deviation of
R, G, B channels. Defaults to None.
pad_size_divisor (int): The size of padded image should be
divisible by ``pad_size_divisor``. Defaults to 1.
pad_value (Number): The padded pixel value. Defaults to 0.
to_rgb (bool): whether to convert image from BGR to RGB.
Defaults to False.
"""
def __init__(self,
mean: Sequence[Number] = None,
std: Sequence[Number] = None,
pad_size_divisor: int = 1,
pad_value: Number = 0,
to_rgb: bool = False,
batch_augments: Optional[dict] = None):
super().__init__()
self.pad_size_divisor = pad_size_divisor
self.pad_value = pad_value
self.to_rgb = to_rgb
if mean is not None:
assert std is not None, 'To enable the normalization in ' \
'preprocessing, please specify both `mean` and `std`.'
# Enable the normalization in preprocessing.
self._enable_normalize = True
self.register_buffer('mean',
torch.tensor(mean).view(-1, 1, 1), False)
self.register_buffer('std',
torch.tensor(std).view(-1, 1, 1), False)
else:
self._enable_normalize = False
if batch_augments:
self.batch_augments = RandomBatchAugment(**batch_augments)
else:
self.batch_augments = None
def forward(self, data: dict, training: bool = False) -> dict:
"""Perform normalization, padding, bgr2rgb conversion based on
``BaseDataPreprocessor``.
Args:
data (dict): data sampled from dataloader.
training (bool): Whether to enable training time augmentation.
Returns:
dict: Data in the same format as the model input.
"""
inputs = self.cast_data(data['inputs'])
if isinstance(inputs, torch.Tensor):
# ------ To RGB ------
if self.to_rgb and inputs.size(1) == 3:
inputs = inputs.flip(1)
# -- Normalization ---
inputs = inputs.float()
if self._enable_normalize:
inputs = (inputs - self.mean) / self.std
# ------ Padding -----
if self.pad_size_divisor > 1:
h, w = inputs.shape[-2:]
target_h = math.ceil(
h / self.pad_size_divisor) * self.pad_size_divisor
target_w = math.ceil(
w / self.pad_size_divisor) * self.pad_size_divisor
pad_h = target_h - h
pad_w = target_w - w
inputs = F.pad(inputs, (0, pad_w, 0, pad_h), 'constant',
self.pad_value)
else:
# The branch if use `pseudo_collate` as the dataloader.
processed_inputs = []
for input_ in inputs:
# ------ To RGB ------
if self.to_rgb and input_.size(0) == 3:
input_ = input_.flip(0)
# -- Normalization ---
input_ = input_.float()
if self._enable_normalize:
input_ = (input_ - self.mean) / self.std
processed_inputs.append(input_)
# Combine padding and stack
inputs = stack_batch(processed_inputs, self.pad_size_divisor,
self.pad_value)
data_samples = data.get('data_samples', None)
sample_item = data_samples[0] if data_samples is not None else None
if isinstance(sample_item, DataSample):
batch_target = None
if 'gt_label' in sample_item:
gt_targets = [sample.gt_label for sample in data_samples]
batch_target = torch.stack(gt_targets).to(self.device)
# ----- Batch Augmentations ----
if training and self.batch_augments is not None:
inputs, batch_target = self.batch_augments(inputs, batch_target)
# ----- scatter targets to data samples ---
if batch_target is not None:
for sample, target in zip(data_samples, batch_target):
sample.set_gt_label(target)
elif isinstance(sample_item, MultiTaskDataSample):
data_samples = self.cast_data(data_samples)
return {'inputs': inputs, 'data_samples': data_samples}
这部分区别在最后,回归只有batch_target,分类的预处理还有个score,我们处理的回归问题并不需要score来描述,用单个label(或是target)就可以描述。
3、train_dataloader
标注文件按上面的函数生成之后看似没什么问题,其实还需要改一个地方(怎么知道要改这里的?报错跳过来的),在mmpretrain/structures/utils.py:
def format_label(value: LABEL_TYPE) -> torch.Tensor:
"""Convert various python types to label-format tensor.
Supported types are: :class:`numpy.ndarray`, :class:`torch.Tensor`,
:class:`Sequence`, :class:`int`, :class:`float`.
Args:
value (torch.Tensor | numpy.ndarray | Sequence | int | float): Label value.
Returns:
:obj:`torch.Tensor`: The foramtted label tensor.
"""
# Handle single number
if isinstance(value, (torch.Tensor, np.ndarray)) and value.ndim == 0:
if np.issubdtype(value.dtype, np.integer):
value = int(value.item())
else:
value = float(value.item())
if isinstance(value, np.ndarray):
if np.issubdtype(value.dtype, np.integer):
value = torch.from_numpy(value).to(torch.long)
else:
value = torch.from_numpy(value).to(torch.float)
elif isinstance(value, Sequence) and not is_str(value):
# Assumption: If the sequence is not of string type, it is of numeric type
value = torch.tensor(value).float()
elif isinstance(value, int):
value = torch.LongTensor([value])
elif isinstance(value, float):
value = torch.FloatTensor([value])
elif not isinstance(value, torch.Tensor):
raise TypeError(f'Type {type(value)} is not an available label type.')
assert value.ndim == 1, \
f'The dims of value should be 1, but got {value.ndim}.'
return value
在dataloader中会调用format_label方法,而这个方法之前是只能接收torch.long类型label的,为了让这个方法兼容分类和回归任务,需要在里面加个判断:如果读到标签是整数转long,否则转float。
4、val_evaluator
新建mmpretrain/evaluation/metrics/regression_label.py:
from itertools import product
from typing import List, Optional, Sequence, Union
import mmengine
import numpy as np
import torch
from mmengine.evaluator import BaseMetric
from mmpretrain.registry import METRICS
def to_tensor(value):
"""Convert value to torch.Tensor."""
if isinstance(value, np.ndarray):
value = torch.from_numpy(value)
elif isinstance(value, Sequence) and not mmengine.is_str(value):
value = torch.tensor(value)
elif not isinstance(value, torch.Tensor):
raise TypeError(f'{type(value)} is not an available argument.')
return value
@METRICS.register_module()
class MAE(BaseMetric):
r"""Mean Absolute Error evaluation metric.
Args:
collect_device (str): Device name used for collecting results from
different ranks during distributed training. Must be 'cpu' or
'gpu'. Defaults to 'cpu'.
prefix (str, optional): The prefix that will be added in the metric
names to disambiguate homonymous metrics of different evaluators.
If prefix is not provided in the argument, self.default_prefix
will be used instead. Defaults to None.
Examples:
>>> import torch
>>> from mmpretrain.evaluation import MAE
>>> y_true = torch.tensor([3, -0.5, 2, 7])
>>> y_pred = torch.tensor([2.5, 0.0, 2, 8])
>>> MAE.calculate(y_pred, y_true)
tensor([0.5])
"""
default_prefix: Optional[str] = 'mae'
def __init__(self,
collect_device: str = 'cpu',
prefix: Optional[str] = None) -> None:
super().__init__(collect_device=collect_device, prefix=prefix)
def process(self, data_batch, data_samples: Sequence[dict]):
"""Process one batch of data samples.
Args:
data_batch: A batch of data from the dataloader.
data_samples (Sequence[dict]): A batch of outputs from the model.
"""
for data_sample in data_samples:
result = dict()
result['pred_score'] = data_sample['pred_score'].cpu()
result['gt_label'] = data_sample['gt_label'].cpu()
# Save the result to `self.results`.
self.results.append(result)
def compute_metrics(self, results: List):
"""Compute the metrics from processed results.
Args:
results (dict): The processed results of each batch.
Returns:
Dict: The computed metrics. The keys are the names of the metrics,
and the values are corresponding results.
"""
metrics = {}
# concat
gt = torch.cat([res['gt_label'] for res in results])
pred = torch.cat([res['pred_score'] for res in results])
mae = self.calculate(pred, gt)
metrics['mae'] = mae.item()
return metrics
@staticmethod
def calculate(
pred: Union[torch.Tensor, np.ndarray, Sequence],
target: Union[torch.Tensor, np.ndarray, Sequence]
) -> torch.Tensor:
"""Calculate the Mean Absolute Error.
Args:
pred (torch.Tensor | np.ndarray | Sequence): The prediction
results.
target (torch.Tensor | np.ndarray | Sequence): The target of
each prediction.
Returns:
torch.Tensor: Mean Absolute Error.
"""
pred = to_tensor(pred)
target = to_tensor(target)
mae = torch.mean(torch.abs(pred - target))
return mae
这个是照着single_label.py中准确率的评估类改的,至此datasets中需要修改的部分完成。
模型
1、type
直接开始重写,在mmpretrain/models/classifiers下新建两个文件base_regressor.py和image_regressor.py。
这里需要指出的问题是,对于强迫症患者,请在mmpretrain/models下新建一个名叫regressors的文件夹并在mmpretrain/models的__init__.py下注册,在新文件夹新建两个文件。上面在分类器的文件夹内新建回归器模块从设计上看是非常难受的,不符合mm系列的设计理念,我这么干只是为了偷懒。
当然还有一个好处,就是好抄。直接把分类器的基类base.py抄过来改个名就是回归器基类base_regressor.py:
from abc import ABCMeta, abstractmethod
from typing import List, Optional, Sequence
import torch
from mmengine.model import BaseModel
from mmengine.structures import BaseDataElement
class BaseRegressor(BaseModel, metaclass=ABCMeta):
"""Base class for regressors.
Args:
init_cfg (dict, optional): Initialization config dict.
Defaults to None.
data_preprocessor (dict, optional): The config for preprocessing input
data. If None, it will use "BaseDataPreprocessor" as type, see
:class:`mmengine.model.BaseDataPreprocessor` for more details.
Defaults to None.
Attributes:
init_cfg (dict): Initialization config dict.
data_preprocessor (:obj:`mmengine.model.BaseDataPreprocessor`): An
extra data pre-processing module, which processes data from
dataloader to the format accepted by :meth:`forward`.
"""
def __init__(self,
init_cfg: Optional[dict] = None,
data_preprocessor: Optional[dict] = None):
super(BaseRegressor, self).__init__(
init_cfg=init_cfg, data_preprocessor=data_preprocessor)
@property
def with_neck(self) -> bool:
"""Whether the regressor has a neck."""
return hasattr(self, 'neck') and self.neck is not None
@property
def with_head(self) -> bool:
"""Whether the regressor has a head."""
return hasattr(self, 'head') and self.head is not None
@abstractmethod
def forward(self,
inputs: torch.Tensor,
data_samples: Optional[List[BaseDataElement]] = None,
mode: str = 'tensor'):
"""The unified entry for a forward process in both training and test.
The method should accept three modes: "tensor", "predict" and "loss":
- "tensor": Forward the whole network and return tensor or tuple of
tensor without any post-processing, same as a common nn.Module.
- "predict": Forward and return the predictions, which are fully
processed to a list of :obj:`BaseDataElement`.
- "loss": Forward and return a dict of losses according to the given
inputs and data samples.
Note that this method doesn't handle neither back propagation nor
optimizer updating, which are done in the :meth:`train_step`.
Args:
inputs (torch.Tensor): The input tensor with shape (N, C, ...)
in general.
data_samples (List[BaseDataElement], optional): The annotation
data of every samples. It's required if ``mode="loss"``.
Defaults to None.
mode (str): Return what kind of value. Defaults to 'tensor'.
Returns:
The return type depends on ``mode``.
- If ``mode="tensor"``, return a tensor or a tuple of tensor.
- If ``mode="predict"``, return a list of
:obj:`mmengine.BaseDataElement`.
- If ``mode="loss"``, return a dict of tensor.
"""
pass
def extract_feat(self, inputs: torch.Tensor):
"""Extract features from the input tensor with shape (N, C, ...).
The sub-classes are recommended to implement this method to extract
features from backbone and neck.
Args:
inputs (Tensor): A batch of inputs. The shape of it should be
``(num_samples, num_channels, *img_shape)``.
"""
raise NotImplementedError
def extract_feats(self, multi_inputs: Sequence[torch.Tensor],
**kwargs) -> list:
"""Extract features from a sequence of input tensor.
Args:
multi_inputs (Sequence[torch.Tensor]): A sequence of input
tensor. It can be used in augmented inference.
**kwargs: Other keyword arguments accepted by :meth:`extract_feat`.
Returns:
list: Features of every input tensor.
"""
assert isinstance(multi_inputs, Sequence), \
'`extract_feats` is used for a sequence of inputs tensor. If you ' \
'want to extract on single inputs tensor, use `extract_feat`.'
return [self.extract_feat(inputs, **kwargs) for inputs in multi_inputs]
两者没有任何不同,声明同样的抽象方法即可,这个文件也可以不要,直接从分类器基类继承也行。但是考虑到ImageRegressor(BaseClassifier)这种写法可读性太差,容易让人不知所云还是单拿出一个文件。
在具体的回归类image_regressor.py中,需要指明我们前面注册的数据预处理方法,其他部分没有变化:
# Copyright (c) OpenMMLab. All rights reserved.
from typing import List, Optional
import torch
import torch.nn as nn
from mmpretrain.registry import MODELS
from mmpretrain.structures import DataSample
from .base_regressor import BaseRegressor
@MODELS.register_module()
class ImageRegressor(BaseRegressor):
"""Image regressor for supervised regression task.
Args:
backbone (dict): The backbone module. See
:mod:`mmpretrain.models.backbones`.
neck (dict, optional): The neck module to process features from
backbone. See :mod:`mmpretrain.models.necks`. Defaults to None.
head (dict, optional): The head module to do prediction and calculate
loss from processed features. See :mod:`mmpretrain.models.heads`.
Notice that if the head is not set, almost all methods cannot be
used except :meth:`extract_feat`. Defaults to None.
pretrained (str, optional): The pretrained checkpoint path, support
local path and remote path. Defaults to None.
train_cfg (dict, optional): The training setting. The acceptable
fields are:
- augments (List[dict]): The batch augmentation methods to use.
More details can be found in
:mod:`mmpretrain.model.utils.augment`.
- probs (List[float], optional): The probability of every batch
augmentation methods. If None, choose evenly. Defaults to None.
Defaults to None.
data_preprocessor (dict, optional): The config for preprocessing input
data. If None or no specified type, it will use
"RegDataPreprocessor" as type. See :class:`RegDataPreprocessor` for
more details. Defaults to None.
init_cfg (dict, optional): the config to control the initialization.
Defaults to None.
"""
def __init__(self,
backbone: dict,
neck: Optional[dict] = None,
head: Optional[dict] = None,
pretrained: Optional[str] = None,
train_cfg: Optional[dict] = None,
data_preprocessor: Optional[dict] = None,
init_cfg: Optional[dict] = None):
if pretrained is not None:
init_cfg = dict(type='Pretrained', checkpoint=pretrained)
data_preprocessor = data_preprocessor or {}
if isinstance(data_preprocessor, dict):
data_preprocessor.setdefault('type', 'RegDataPreprocessor')
data_preprocessor.setdefault('batch_augments', train_cfg)
data_preprocessor = MODELS.build(data_preprocessor)
elif not isinstance(data_preprocessor, nn.Module):
raise TypeError('data_preprocessor should be a `dict` or '
f'`nn.Module` instance, but got '
f'{type(data_preprocessor)}')
super(ImageRegressor, self).__init__(
init_cfg=init_cfg, data_preprocessor=data_preprocessor)
if not isinstance(backbone, nn.Module):
backbone = MODELS.build(backbone)
if neck is not None and not isinstance(neck, nn.Module):
neck = MODELS.build(neck)
if head is not None and not isinstance(head, nn.Module):
head = MODELS.build(head)
self.backbone = backbone
self.neck = neck
self.head = head
def forward(self,
inputs: torch.Tensor,
data_samples: Optional[List[DataSample]] = None,
mode: str = 'tensor'):
"""The unified entry for a forward process in both training
and test.
The method should accept three modes: "tensor", "predict" and "loss":
- "tensor": Forward the whole network and return tensor(s) without any
post-processing, same as a common PyTorch Module.
- "predict": Forward and return the predictions, which are fully
processed to a list of :obj:`DataSample`.
- "loss": Forward and return a dict of losses according to the given
inputs and data samples.
Args:
inputs (torch.Tensor): The input tensor with shape
(N, C, ...) in general.
data_samples (List[DataSample], optional): The annotation
data of every samples. It's required if ``mode="loss"``.
Defaults to None.
mode (str): Return what kind of value. Defaults to 'tensor'.
Returns:
The return type depends on ``mode``.
- If ``mode="tensor"``, return a tensor or a tuple of tensor.
- If ``mode="predict"``, return a list of
:obj:`mmpretrain.structures.DataSample`.
- If ``mode="loss"``, return a dict of tensor.
"""
if mode == 'tensor':
feats = self.extract_feat(inputs)
return self.head(feats) if self.with_head else feats
elif mode == 'loss':
return self.loss(inputs, data_samples)
elif mode == 'predict':
return self.predict(inputs, data_samples)
else:
raise RuntimeError(f'Invalid mode "{mode}".')
def extract_feat(self, inputs, stage='neck'):
"""Extract features from the input tensor with shape (N, C, ...).
Args:
inputs (Tensor): A batch of inputs. The shape of it should be
``(num_samples, num_channels, *img_shape)``.
stage (str): Which stage to output the feature. Choose from:
- "backbone": The output of backbone network. Returns a tuple
including multiple stages features.
- "neck": The output of neck module. Returns a tuple including
multiple stages features.
- "pre_logits": The feature before the final regression
linear layer. Usually returns a tensor.
Defaults to "neck".
Returns:
tuple | Tensor: The output of specified stage.
The output depends on detailed implementation. In general, the
output of backbone and neck is a tuple and the output of
pre_logits is a tensor.
"""
assert stage in ['backbone', 'neck', 'pre_logits'], \
(f'Invalid output stage "{stage}", please choose from "backbone", '
'"neck" and "pre_logits"')
x = self.backbone(inputs)
if stage == 'backbone':
return x
if self.with_neck:
x = self.neck(x)
if stage == 'neck':
return x
assert self.with_head and hasattr(self.head, 'pre_logits'), \
"No head or the head doesn't implement `pre_logits` method."
return self.head.pre_logits(x)
def loss(self, inputs: torch.Tensor,
data_samples: List[DataSample]) -> dict:
"""Calculate losses from a batch of inputs and data samples.
Args:
inputs (torch.Tensor): The input tensor with shape
(N, C, ...) in general.
data_samples (List[DataSample]): The annotation data of
every samples.
Returns:
dict[str, Tensor]: a dictionary of loss components
"""
feats = self.extract_feat(inputs)
return self.head.loss(feats, data_samples)
def predict(self,
inputs: torch.Tensor,
data_samples: Optional[List[DataSample]] = None,
**kwargs) -> List[DataSample]:
"""Predict results from a batch of inputs.
Args:
inputs (torch.Tensor): The input tensor with shape
(N, C, ...) in general.
data_samples (List[DataSample], optional): The annotation
data of every samples. Defaults to None.
**kwargs: Other keyword arguments accepted by the ``predict``
method of :attr:`head`.
"""
feats = self.extract_feat(inputs)
return self.head.predict(feats, data_samples, **kwargs)
def get_layer_depth(self, param_name: str):
"""Get the layer-wise depth of a parameter.
Args:
param_name (str): The name of the parameter.
Returns:
Tuple[int, int]: The layer-wise depth and the max depth.
"""
if hasattr(self.backbone, 'get_layer_depth'):
return self.backbone.get_layer_depth(param_name, 'backbone.')
else:
raise NotImplementedError(
f"The babckone {type(self.backbone)} doesn't "
'support `get_layer_depth` by now.')
2、head
头的设置包括两点,一个是回归头改写,需要把分类头去掉分类相关内容;一个是损失函数。
头的位置在mmpretrain/models/heads,新建两个文件,一个是把分类头基类去掉分类信息的回归头基类,另一个是继承这个基类的线性回归头。
回归头
回归头基类regression_head.py:
from typing import List, Optional, Tuple
import torch
import torch.nn as nn
from mmengine.model import BaseModule
from mmpretrain.registry import MODELS
from mmpretrain.structures import DataSample
@MODELS.register_module()
class RegHead(BaseModule):
"""Regression head.
Args:
loss (dict): Config of regression loss. Defaults to
``dict(type='MSELoss', loss_weight=1.0)``.
init_cfg (dict, optional): the config to control the initialization.
Defaults to None.
"""
def __init__(self,
loss: dict = dict(type='MSELoss', loss_weight=1.0),
init_cfg: Optional[dict] = None):
super(RegHead, self).__init__(init_cfg=init_cfg)
if not isinstance(loss, nn.Module):
loss = MODELS.build(loss)
self.loss_module = loss
def pre_logits(self, feats: Tuple[torch.Tensor]) -> torch.Tensor:
"""The process before the final regression head."""
return feats[-1]
def forward(self, feats: Tuple[torch.Tensor]) -> torch.Tensor:
"""The forward process."""
pre_logits = self.pre_logits(feats)
return pre_logits
def loss(self, feats: Tuple[torch.Tensor], data_samples: List[DataSample],
**kwargs) -> dict:
"""Calculate losses from the regression score."""
reg_score = self(feats)
losses = self._get_loss(reg_score, data_samples, **kwargs)
return losses
def _get_loss(self, reg_score: torch.Tensor,
data_samples: List[DataSample], **kwargs):
"""Unpack data samples and compute loss."""
target = torch.stack([i.gt_label for i in data_samples])
losses = dict()
loss = self.loss_module(
reg_score, target, avg_factor=reg_score.size(0), **kwargs)
losses['loss'] = loss
return losses
def predict(self,
feats: Tuple[torch.Tensor],
data_samples: Optional[List[Optional[DataSample]]] = None
) -> List[DataSample]:
"""Inference without augmentation."""
reg_score = self(feats)
predictions = self._get_predictions(reg_score, data_samples)
return predictions
def _get_predictions(self, reg_score, data_samples):
"""Post-process the output of head."""
out_data_samples = []
if data_samples is None:
data_samples = [None for _ in range(reg_score.size(0))]
for data_sample, score in zip(data_samples, reg_score):
if data_sample is None:
data_sample = DataSample()
data_sample.set_pred_score(score.detach())
out_data_samples.append(data_sample)
return out_data_samples
线性回归头linear_regression_head.py:
from typing import Optional, Tuple
import torch
import torch.nn as nn
from mmpretrain.registry import MODELS
from .regression_head import RegHead
@MODELS.register_module()
class LinearRegHead(RegHead):
"""Linear regression head.
Args:
num_outputs (int): Number of regression outputs.
in_channels (int): Number of channels in the input feature map.
init_cfg (dict, optional): the config to control the initialization.
Defaults to ``dict(type='Normal', layer='Linear', std=0.01)``.
"""
def __init__(self,
num_outputs: int,
in_channels: int,
init_cfg: Optional[dict] = dict(
type='Normal', layer='Linear', std=0.01),
**kwargs):
super(LinearRegHead, self).__init__(init_cfg=init_cfg, **kwargs)
self.in_channels = in_channels
self.num_outputs = num_outputs
if self.num_outputs <= 0:
raise ValueError(
f'num_outputs={num_outputs} must be a positive integer')
self.fc = nn.Linear(self.in_channels, self.num_outputs)
def pre_logits(self, feats: Tuple[torch.Tensor]) -> torch.Tensor:
"""The process before the final regression head."""
return feats[-1]
def forward(self, feats: Tuple[torch.Tensor]) -> torch.Tensor:
"""The forward process."""
pre_logits = self.pre_logits(feats)
# The final regression head.
reg_score = self.fc(pre_logits)
return reg_score
头的实现没什么好说的,非常简单,该抄抄该改改。
损失函数
loss的位置在mmpretrain/models/losses,新建mae_loss.py,表示使用mae作为损失函数(不是mae论文的损失函数):
# Copyright (c) OpenMMLab. All rights reserved.
import torch.nn as nn
import torch.nn.functional as F
from mmpretrain.registry import MODELS
from .utils import weight_reduce_loss
@MODELS.register_module()
class MAELoss(nn.Module):
"""Mean Absolute Error (MAE) loss.
Args:
reduction (str): The method used to reduce the loss.
Options are "none", "mean" and "sum". Defaults to 'mean'.
loss_weight (float): Weight of the loss. Defaults to 1.0.
"""
def __init__(self,
reduction='mean',
loss_weight=1.0):
super(MAELoss, self).__init__()
self.reduction = reduction
self.loss_weight = loss_weight
def forward(self,
pred,
target,
weight=None,
avg_factor=None,
reduction_override=None,
**kwargs):
assert reduction_override in (None, 'none', 'mean', 'sum')
reduction = (
reduction_override if reduction_override else self.reduction)
# element-wise losses
loss = F.l1_loss(pred, target, reduction='none')
# apply weights and do the reduction
if weight is not None:
weight = weight.float()
loss = self.loss_weight * weight_reduce_loss(
loss, weight=weight, reduction=reduction, avg_factor=avg_factor)
return loss
F.l1_loss的reduction给到none,reduction在下面用mmlab自己的轮子。
这里需要提一下,尽管mm系列兼容pytorch,但是能用mm自己封装的轮子一般还是用mm的(封装了肯定有mm认为更好的设计在里面),我只有在搞不清mm api(最好还是查清楚)的情况下才会用更底层的框架。
最后训练的config:
# Only for evaluation
_base_ = [
'../_base_/default_runtime.py'
]
model = dict(
type='ImageRegressor',
backbone=dict(
type='SwinTransformerV2',
arch='large',
img_size=384,
window_size=[24, 24, 24, 12],
pretrained_window_sizes=[12, 12, 12, 6],
drop_path_rate=0.2,
frozen_stages=2,
init_cfg=dict(
type='Pretrained',
checkpoint=r'C:\Users\zyan\Downloads\swinv2-large-w24_in21k-pre_3rdparty_in1k-384px_20220803-3b36c165.pth',
prefix='backbone'
)
),
neck=[
dict(type='GlobalAveragePooling')
],
head=dict(
type='LinearRegHead',
in_channels=1536,
num_outputs=1,
loss=dict(type='MAELoss', loss_weight=1.0),
),
train_cfg=dict(augments=[
dict(type='Mixup', alpha=0.4)
])
)
# dataset settings
dataset_type = 'RegressionDataset'
data_preprocessor = dict(
# RGB format normalization parameters
mean=[123.675, 116.28, 103.53],
std=[58.395, 57.12, 57.375],
# convert image from BGR to RGB
to_rgb=True,
)
train_pipeline = [
dict(type='LoadImageFromFile'),
dict(
type='RandomResizedCrop',
scale=384,
backend='pillow',
interpolation='bicubic'),
dict(type='RandomFlip', prob=0.5, direction='horizontal'),
dict(type='PackInputs'),
]
test_pipeline = [
dict(type='LoadImageFromFile'),
dict(type='Resize', scale=384, backend='pillow', interpolation='bicubic'),
dict(type='PackInputs'),
]
train_dataloader = dict(
batch_size=32,
num_workers=5,
dataset=dict(
type=dataset_type,
data_root=r'H:\data\sow\fat_cropped_new',
ann_file=r'H:\data\sow\fat_cropped_new\annotations\train.txt',
data_prefix='train',
pipeline=train_pipeline),
sampler=dict(type='DefaultSampler', shuffle=True),
)
val_dataloader = dict(
batch_size=32,
num_workers=5,
dataset=dict(
type=dataset_type,
data_root=r'H:\data\sow\fat_cropped_new',
ann_file=r'H:\data\sow\fat_cropped_new\annotations\val.txt',
data_prefix='val',
pipeline=test_pipeline),
sampler=dict(type='DefaultSampler', shuffle=False),
)
val_evaluator = [
dict(type='MAE'),
]
test_dataloader = dict(
batch_size=32,
num_workers=5,
dataset=dict(
type=dataset_type,
data_root=r'H:\data\sow\fat_cropped_new',
ann_file=r'H:\data\sow\fat_cropped_new\annotations\test.txt',
data_prefix='test',
pipeline=test_pipeline),
sampler=dict(type='DefaultSampler', shuffle=False),
)
test_evaluator = [
dict(type='MAE'),
]
# for batch in each gpu is 128, 8 gpu
# lr = 5e-4 * 128 * 8 / 512 = 0.001
optim_wrapper = dict(
optimizer=dict(
type='AdamW',
lr=5e-4 * 1024 / 512,
weight_decay=0.05,
eps=1e-8,
betas=(0.9, 0.999)),
paramwise_cfg=dict(
norm_decay_mult=0.0,
bias_decay_mult=0.0,
flat_decay_mult=0.0,
custom_keys={
'.absolute_pos_embed': dict(decay_mult=0.0),
'.relative_position_bias_table': dict(decay_mult=0.0)
}),
)
# learning policy
param_scheduler = [
# warm up learning rate scheduler
dict(
type='LinearLR',
start_factor=1e-3,
by_epoch=True,
end=20,
# update by iter
convert_to_iter_based=True),
# main learning rate scheduler
dict(type='CosineAnnealingLR', eta_min=1e-5, by_epoch=True, begin=20)
]
# train, val, test setting
train_cfg = dict(by_epoch=True, max_epochs=300, val_interval=1)
val_cfg = dict()
test_cfg = dict()
# NOTE: `auto_scale_lr` is for automatically scaling LR,
# based on the actual training batch size.
auto_scale_lr = dict(base_batch_size=1024)
推理
仿照mmpretrain/apis/image_classification.py中图片分类推理模块ImageClassificationInferencer,写自己的回归推理模块,让chatgpt帮忙写一个,别忘注册:
from pathlib import Path
from typing import Callable, List, Optional, Union
import numpy as np
import cv2
import torch
from mmcv.image import imread
from mmengine.config import Config
from mmengine.dataset import Compose, default_collate
from mmengine.device import get_device
from mmengine.infer import BaseInferencer
from mmengine.model import BaseModel
from mmengine.runner import load_checkpoint
from mmpretrain.registry import TRANSFORMS
from mmpretrain.structures import DataSample
from .model import get_model, list_models
ModelType = Union[BaseModel, str, Config]
InputType = Union[str, np.ndarray, list]
class ImageRegressionInferencer(BaseInferencer):
"""The inferencer for regression.
Args:
model (BaseModel | str | Config): A model name or a path to the config
file, or a :obj:`BaseModel` object. The model name can be found
by ``ImageRegressionInferencer.list_models()`` and you can also query it
in :doc:`/modelzoo_statistics`.
weights (str, optional): Path to the checkpoint. If None, it will try
to find a pre-defined weight from the model you specified
(only work if the ``model`` is a model name). Defaults to None.
device (str, optional): Device to run inference. If None, use CPU or
the device of the input model. Defaults to None.
Example:
1. Use a pre-trained model in MMPreTrain to inference an image.
>>> from mmpretrain import ImageRegressionInferencer
>>> inferencer = ImageRegressionInferencer('resnet50_8xb32_in1k')
>>> inferencer('demo/demo.JPEG')
[{'pred_score': 0.6649367809295654}]
2. Use a config file and checkpoint to inference multiple images on GPU.
>>> from mmpretrain import ImageRegressionInferencer
>>> inferencer = ImageRegressionInferencer(
model='configs/resnet/resnet50_8xb32_in1k.py',
weights='https://download.openmmlab.com/mmclassification/v0/resnet/resnet50_8xb32_in1k_20210831-ea4938fc.pth',
device='cuda')
>>> inferencer(['demo/dog.jpg', 'demo/bird.JPEG'])
"""
def __init__(
self,
model: ModelType,
pretrained: Union[bool, str] = True,
device: Union[str, torch.device, None] = None,
) -> None:
device = device or get_device()
if isinstance(model, BaseModel):
if isinstance(pretrained, str):
load_checkpoint(model, pretrained, map_location='cpu')
model = model.to(device)
else:
model = get_model(model, pretrained, device)
model.eval()
self.config = model.config
self.model = model
self.pipeline = self._init_pipeline(self.config)
self.collate_fn = default_collate
def __call__(self, inputs: InputType, batch_size: int = 1) -> dict:
"""Call the inferencer.
Args:
inputs (str | array | list): The image path or array, or a list of
images.
batch_size (int): Batch size. Defaults to 1.
Returns:
list: The inference results.
"""
return super().__call__(inputs, batch_size=batch_size)
def _init_pipeline(self, cfg: Config) -> Callable:
test_pipeline_cfg = cfg.test_dataloader.dataset.pipeline
if test_pipeline_cfg[0]['type'] == 'LoadImageFromFile':
# Image loading is finished in `self.preprocess`.
test_pipeline_cfg = test_pipeline_cfg[1:]
test_pipeline = Compose(
[TRANSFORMS.build(t) for t in test_pipeline_cfg])
return test_pipeline
def preprocess(self, inputs: List[InputType], batch_size: int = 1):
def load_image(input_):
img = imread(input_)
if img is None:
raise ValueError(f'Failed to read image {input_}.')
return dict(
img=img,
img_shape=img.shape[:2],
ori_shape=img.shape[:2],
)
pipeline = Compose([load_image, self.pipeline])
chunked_data = self._get_chunk_data(map(pipeline, inputs), batch_size)
yield from map(self.collate_fn, chunked_data)
def postprocess(self,
preds: List[DataSample],
visualization: List[np.ndarray],
return_datasamples=False) -> dict:
if return_datasamples:
return preds
results = []
for data_sample in preds:
pred_scores = data_sample.pred_score
pred_score = float(pred_scores.item())
result = {
'pred_score': pred_score,
}
results.append(result)
return results
def visualize(self,
ori_inputs: List[InputType],
preds: List[DataSample],
show: bool = False,
wait_time: int = 0,
resize: Optional[int] = None,
rescale_factor: Optional[float] = None,
draw_score=True,
show_dir=None):
if not show and show_dir is None:
return None
visualization = []
for i, (input_, data_sample) in enumerate(zip(ori_inputs, preds)):
image = imread(input_)
if isinstance(input_, str):
# The image loaded from path is BGR format.
image = image[..., ::-1]
name = Path(input_).stem
else:
name = str(i)
pred_score = data_sample.pred_score.item()
# draw predicted score on the image
if draw_score:
cv2.putText(image, f"Prediction: {pred_score}", (10, 30), cv2.FONT_HERSHEY_SIMPLEX, 0.9, (0, 255, 0), 2)
if show_dir is not None:
show_dir = Path(show_dir)
show_dir.mkdir(exist_ok=True)
out_file = str((show_dir / name).with_suffix('.png'))
cv2.imwrite(out_file, image)
else:
cv2.imshow("Predictions", image)
cv2.waitKey(wait_time)
visualization.append(image)
return visualization
@staticmethod
def list_models(pattern: Optional[str] = None):
"""List all available model names.
Args:
pattern (str | None): A wildcard pattern to match model names.
Returns:
List[str]: a list of model names.
"""
return list_models(pattern=pattern, task='Regression')
上面的可视化方法我没有验证,继承的父类要求必须实现这个方法。我用chatgpt4生成了一个,如果需要用此功能需要自行验证。
推理demo:
from mmengine.fileio import dump
from rich import print_json
from mmpretrain.apis import ImageRegressionInferencer
def main():
model = r'F:\workspace\mmpretrain\configs\swin_transformer_v2\swinv2-large-w24_in21k-pre_16xb64_in1k-384px.py'
weight = r'F:\workspace\mmpretrain\work_dirs\swinv2-large-w24_in21k-pre_16xb64_in1k-384px\epoch_90.pth'
img = r'H:\data\holographic_body\train\time_20230308101458_weight_8.0_lenght_42.0_width_14.0_height_30.0\time_20230308101458_weight_8.0_lenght_42.0_width_14.0_height_30.0_fps_347_MAG_rgb.jpg'
inferencer = ImageRegressionInferencer(model, pretrained=weight)
result = inferencer(img)[0]
# show the results
print_json(dump(result.pop('pred_score'), file_format='json', indent=4))
if __name__ == '__main__':
main()
demo可以输出图片的回归值。我们还可以调gradio用很简单的代码把模型放到web演示:
from mmpretrain.apis import ImageRegressionInferencer
import gradio as gr
def predict(img_path):
model = r'F:\workspace\mmpretrain\configs\swin_transformer_v2\swinv2-large-w24_in21k-pre_16xb64_in1k-384px.py'
weight = r'F:\workspace\mmpretrain\work_dirs\swinv2-large-w24_in21k-pre_16xb64_in1k-384px\epoch_90.pth'
inferencer = ImageRegressionInferencer(model, pretrained=weight)
result = inferencer(img_path)[0]
return result.pop('pred_score')
iface = gr.Interface(
fn=predict, # the function to wrap
inputs=gr.inputs.Image(), # the input type
outputs="number", # the output type
)
iface.launch()
运行后有个界面,可以把图片拖上去推理出我们想要的回归值:
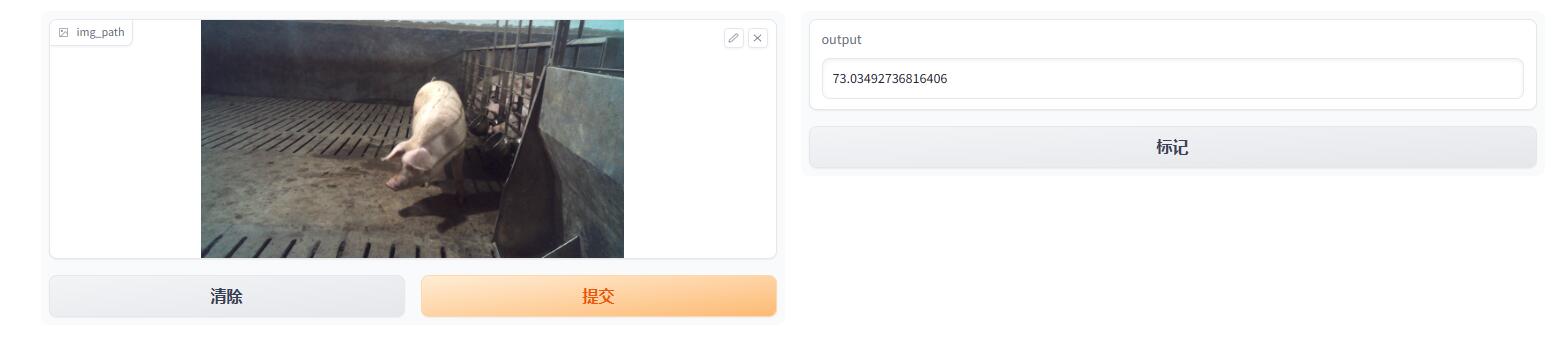
总结
整体看下来,得益于mm系列的模块化设计,修改起来的确非常清晰明确,也没有什么难点,只是要改的模块稍微多一点,需要一点细心。
博主根据任务需求还做了一系列魔改操作(没放上来),有一部分修改比较复杂,不过都可以依托mm框架很好的实现。可见此系列灵活度是很高的,很适合各种diy操作。相比只能调参的nvidia tao toolkit面向不同的用户群体。
本文由 aboom 原创,转载请注明出处。