目的:yolov5训练出的pytorch模型需要转换成tensorrt模型扔到triton里部署
需求:
1、为加快推理速度,需要把fp32精度的模型转成fp16
2、为支持yolov5动态padding和批推理,输入的batch和图片size需要是动态的
版本:
yolov5——v6.1;
triton docker镜像——22.08;
TensorRT——8.4.2.4;
cudnn——8.2.1.32;
CUDA Toolkit——11.3.1
流程:
1、pt转onnx
首先需要把pytorch模型转成onnx,yolov5尽管自带转engine的方法,但是v6.1版本--dynamic动态输入和--half fp16半精度参数不兼容,这两个参数一起用会报错--half not compatible with --dynamic.:
 因此需要先单独转成onnx,onnx转换命令:
因此需要先单独转成onnx,onnx转换命令:python export.py --weights last.pt --img 640 --dynamic --batch 1 --opset 13 --include onnx
需要注意TensorRT8以上onnx算子库至少要指定为13,默认是12如果用默认值到时候转engine会出问题。
去onnx可视化 看一下转出来的onnx模型:
 没问题,输入输出的batch和size都是动态的,不再是固定值。
没问题,输入输出的batch和size都是动态的,不再是固定值。
2、fp32 onnx转fp16 onnx
import onnxmltools
from onnxmltools.utils.float16_converter import convert_float_to_float16
# Update the input name and path for your ONNX model
input_onnx_model = 'last.onnx'
# Change this path to the output name and path for your float16 ONNX model
output_onnx_model = 'last.onnx'
# Load your model
onnx_model = onnxmltools.utils.load_model(input_onnx_model)
# Convert tensor float type from your input ONNX model to tensor float16
onnx_model = convert_float_to_float16(onnx_model)
# Save as protobuf
onnxmltools.utils.save_model(onnx_model, output_onnx_model)
import onnx
model_onnx = onnx.load('last.onnx')
#onnx.checker.check_model(model_onnx)
print(model_onnx.graph.output)
使用onnxmltools转换,如果可视化会发现新模型的输入输出变为float16,说明转换成功。
3、onnx转TensorRT engine模型
和onnx是同样的问题,--dynamic和--half不能同时用,我们在命令行指定--dynamic,--half的内容去代码里改:
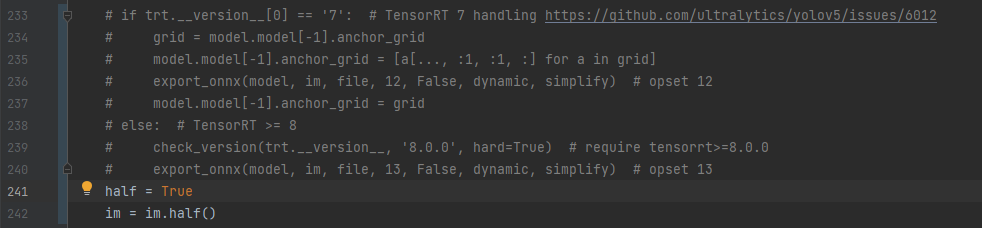 在yolov5 export.py中找到export_engine函数,把原pt模型和转出来的fp16 onnx模型放到同一路径下(名字需要相同),注释掉export_engine中转onnx的部分,增加两行代码,指定半精度转换。
在yolov5 export.py中找到export_engine函数,把原pt模型和转出来的fp16 onnx模型放到同一路径下(名字需要相同),注释掉export_engine中转onnx的部分,增加两行代码,指定半精度转换。
 再在export_engine中找到dynamic判断的部分,把
再在export_engine中找到dynamic判断的部分,把profile.set_shape中的维度改成自己的值,这个方法四个参数分别是输入的名字,最小维度、最佳维度、最大维度,输入允许在最小和最大间动态,最佳维度可以随便写一个中间的值,一般和最大维度一样即可。
如果用TensorRT自带的trtexec工具转,维度对应的参数分别是"--minShapes --optShapes --maxShapes",具体可以查看trtexec的官方介绍trtexec官方文档
转换命令:python export.py --weights last.pt --img 640 --dynamic --batch 1 --include engine --device 0 --verbose
成功会显示success。
如果TensorRT版本在8.2会报一个错误:
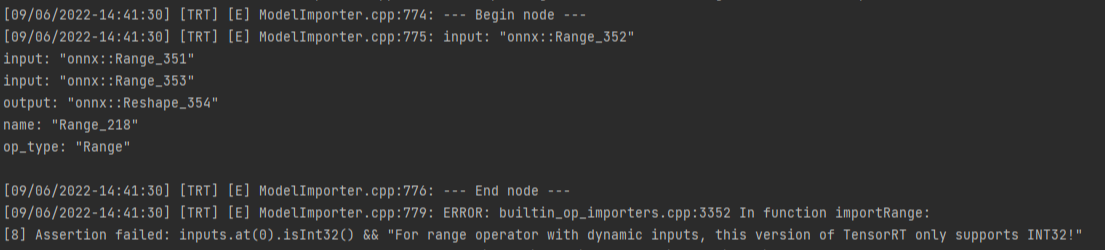 TensorRT 8.4支持Range算子,升级TensorRT版本即可解决。
TensorRT 8.4支持Range算子,升级TensorRT版本即可解决。
4、engine模型部署到triton
把转出来的模型重命名为model.plan,放到模型/1/model.plan。
镜像要选22.08的(转换的TensorRT版本要和triton docker镜像带的TensorRT版本一致,triton镜像带的软件版本可以去官网查看triton镜像版本对应关系 )。
输入curl localhost:8000/v2/models/your_model_name/config查看模型输出,your_model_name换成自己模型的名字,8000是triton启动http输出的端口号。
如果在config.pbtxt指定max_batch_size,batch在triton里是隐式的,即batch维度不会显式地显示在输入输出中。input和output中的动态维度用-1表示,不带batch维度。如果不加max_batch_size,输入输出最前面需要用-1指定动态batch维度。
5、其他问题
模型转换的显卡系列和部署的显卡系列必须相同,如果在30系显卡转换,在20系显卡部署,则会报算力不同的错误,20系列是compute 7.5,30系列是compute 8.6。